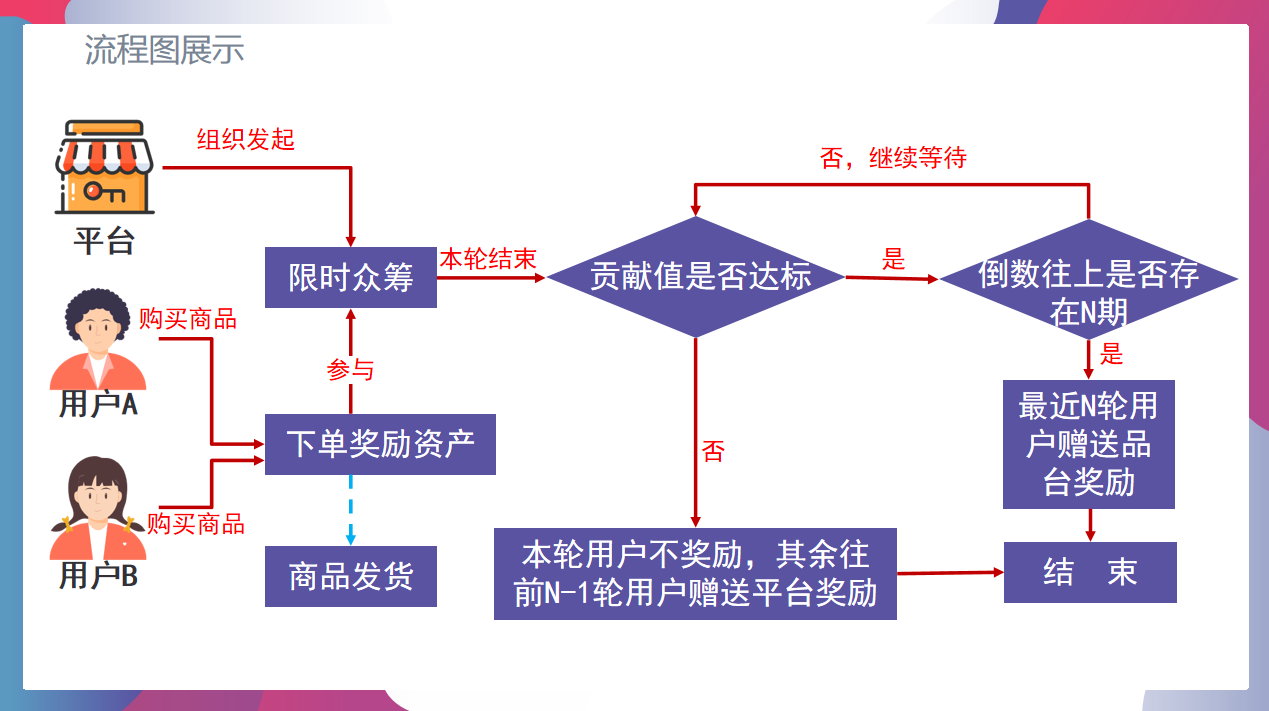

向各位企业家及创业者朋友们问好,我是的门门(陈景尧),这期门门给大伙儿讲讲承载过亿的商业模式——泰山众筹
泰山众筹模式已经走了4个多年头,目前仍在运行。

泰山众筹模式:
一、无泡沫——安全长久
所有的互联网金融项目的死穴就是泡沫无法消除,泰山全球首创止损重生机制,科学消除泡沫,彻底解决行业泡沫痛点,实现安全长久赚大钱;
二、返本息——更放心
以往的项目一旦新增业绩跟不上,崩盘,投资者几乎血本无归,泰山全球个第提出止损返本息,新增业绩一旦跟不上,立即止损返本65%—75%—。让投资者本金有保障,投资更放心;
三、新规则——不伤人脉
以往的项目一旦崩盘,后参与者买单、血本无归,大伤人脉。泰山改写行业买单规则、后参与者返本,不伤人脉。
四、重生机制——生生不息
所有的项目都会从生到死,这是事物发展的必然规律,但很多投资者参与一个项目、只想项目生时的收益,不想项目死时的风险,掩耳盗铃、自欺欺人、这是非常不成熟的投资心理。泰山一旦出现众筹失败,就会立即启动止损重生机制,返本推倒重来,生生不息。
以上就是泰山众筹的四大拐点、四大亮点、也是泰山众筹的四大价值:
1、彻底解决了项目泡沫无法消除的问题;
2、彻底解决了投资者血本无归的问题;
3、彻底解决了推广者伤人脉的问题;
4、彻底解决了项目生命周期短命的问题;
泰山止损重生机制,全球行业风向标,必将引行业健康持续发展。
泰山众筹+止损重生+复利+生生不息
以科技为引信,以文化为纽带,以创新为驱动,让产品名副其实,让客户功成名就
门门祝各位企业家,创业者朋友们,根深叶茂无疆业,源远流长有道财!
分享模式,分享知识,分享系统,分享价值。如需完整方案,软件开发,模式策划,需要了解电商软件等相关信息或者其他方面的电商问题的读者,可以留下联系方式私信小编,门门都会一一回复,搜索门门,千篇商业方案解析给你听!
扩展资料:
以前经历的一个线上缺陷说起,聊一下软件质量保障的巡检技术。
我认为质量保障的手段有主动发现与被动发现之分。通常,大家所听到的测试左移,例如测试参与的codereview、每日运行的接口自动化用例以及软件测试异常注入等,可以划分为主动发现缺陷的手段,可以理解为对缺陷发起主动“进攻”。而项目上线后,主动缺陷发现手段则不便在生产环境继续使用,当然根据测试右移的思想,我们可以通过生产环境服务监控、错误日志发现等被动方式监测到线上的抛错问题,可以将此手段归类为被动发现手段。主动和被动手段没有哪种更好之分,都是质量保障的一部分,二者结合方可提升业务测试质量。
大家都知道,软件测试是无法穷举测试的,即测试只能证明软件存在缺陷,不能证明软件没有缺陷。主动手段不能保障产品发布后就不会有缺陷产生,因而可以使用被动手段弥补,监控风险较高的功能or服务。
此外,做过接口自动化的小伙伴都知道,自动化用例是否有效,可以将发现的缺陷数作为一个衡量指标,这样测试人就必须尽可能丰富用例的断言内容,例如接口断言、DB断言等。纵然如此,断言在某些场景下仍然存在不足。因为有时候即便不合理的业务输入也可能存在正确的输出结果。介绍的案例就是这样的一个case。
案例
业务场景是这样的,存在一个服务A,可以根据输入内容,将内容中存在的MP3信息解析出来,然后转存到我们自己的服务器上,生成一个MP3的链接地址,并在前端页面(用户端)渲染出来(允许用户点击播放MP3内容)。
起初测试同学测试这个服务的时候,没有考虑MP3本身的可播放性,只是通过页面展示的MP3图标作为预期结果(当然测试在真实测试过程也会主动去点击播放,但是问题是mp3太多,所以不能全部都点击播放一遍)。接口测试也是只对接口返回的MP3标签内容进行check,没有对其可用性进行断言。
突然有天就接到了来自业务方的反馈,说C端用户投诉APP端展示的MP3内容无法播放,影响了用户体验。我们这边开发通过排查发现,确实在转存服务器的过程有些MP3文件本身损坏,导致无法播放。开发意识到服务器上仍然存在损坏的mp3文件,需要对服务器上的Mp3文件进行一次全量的扫描。因为数量之大,肯定不可能考虑人工check,只能使用自动化手段,而我通过研究MP3自身属性发现,损坏的MP3属性相比可播放的Mp3是不完整的,可以通过自动化的手段在线扫描MP3自身属性,如果发现MP3某属性缺失可判定为文件损坏。
通过FFMpeg可以查看MP3属性
有效的MP3会有Metadata,而无效的MP3则无,可以肯定的是损坏的MP3属性是不完整的。
Metadata: comment : 5023415_499131 genre : 5023415_499131 encoder : Lavf56.4.101 disc : 1 track : 1 artist : Dan Gibson title : The Canon Stirs album : Pachelbel: Forever by the Sea Duration: 00:04:25.95, start: 0.025056, bitrate: 331 kb/s Stream #0:0: Audio: mp3, 44100 Hz, stereo, fltp, 320 kb/s Stream #0:1: Video: png, rgba(pc), 500x500, 90k tbr, 90k tbn (attached pic) Metadata: comment : Other解决方案
为了解决这个问题,针对存量MP3,我们通过脚本进行一次全量扫描,发现损坏MP3即下架;针对增量MP3,将脚本部署到服务器作为巡检脚本,通过Jenkins调度此任务,每日定时对当天产生的MP3文件进行扫描,发现损坏MP3,告知相关同学进行重传或下架。
时间想到的使用Python的eyeD3库进行MP3属性信息获取,可以使用如下代码查看MP3标签信息。
如果有效MP3,则输出,否则则会报错。
所以有时候自动化并不一定需要多高深的技术来实现,简简单单代码就能实现自动化(当然上述代码不是用来巡检的脚本,因为量比较大,需要多进程并行检测)。改进后通过巡检技术方案检测损坏MP3的流程图如下:因为是离线巡检问题数据,这个方案仍然存在一定的延时性,但是我们当时的业务对实效性要求不高,只要当天能把入库的MP3巡检完毕即可,这样也可以解决问题了。
思考
巡检技术其实不是什么高深的技术,可以理解为接口自动化的补充,去做一些直接通过断言无法做(抑或断言成本高)的事情。对于实效性要求不高的业务,可以借助异步手段实现数据准确性校验。对于实效性高的业务,建议让开发对服务多打日志,通过检测错误日志(当然错误日志也是有等级的,这个可以根据基于业务自身定义,级别较高的需要立刻响应)实现时间发现问题并报警。
此外,为何借助于Jenkins实现任务调度,难道使用Linux服务器自身的Crontab实现定时任务不行吗?答案是可以的,但是Jenkins更易于巡检任务的管理,特别是当巡检任务比较多的时候,可以将Jenkins理解为一个简单的巡检任务管理平台,在Jenkins服务器上部署巡检脚本、报警等配置,算是一整套的解决方案(部署->调度->报警)。当然了,Jenkins管理巡检任务也有缺陷,例如巡检发现的问题统计,如果想做的更好建议开发简单的巡检平台,考虑从脚本开发->部署->调度->报警->数据统计全流程覆盖。实现也简单,工作量更多在于前端管理系统开发,调度/部署层 可以基于Jenkins OpenAPI实现(以后有机会详细介绍Jenkins),直接调用接口即可。其他的可以额外开发接口即可。